

Y si usamos los CronJobs en Kubernetes

Soy Roxs 👩💻| Software Developer | DevOps | DevSecOps | en @295DevOps 🖼 Content Creator. No se puede crecer si no estas dispuesto a saltar a la zona de peligro 🔥
Introducción
Kubernetes se ha convertido rápidamente en la herramienta estándar para la gestión de infraestructuras containerizadas. Kubernetes cuenta con variedad de recursos de carga de trabajo disponibles para controlar y administrar pods y contenedores, los más comunes siendo:
- Deployments
- ReplicaSets
- StatefulSets
Éstos se utilizan tanto para crear sistemas como para controlar el comportamiento deseado de las diferentes partes. Aunque estos recursos tienen diferentes propósitos y funcionalidades, todos comparten la operativa de mantener los sistemas levantados en caso de fallo, evaluando el estado de contenedores, y reiniciando o reprogramando (“rescheduling”) las partes relevantes en caso necesario.
No obstante, hay otros recursos de carga de trabajo disponibles:
- Job
- Cronjobs
En esta entrada de blog, nos centramos en los Cronjobs: su función y las opciones de customización disponibles.
Cómo funcionan los CronJobs en Kubernetes
CronJob ayuda a ejecutar su tarea en un horario determinado para que pueda definir a qué hora debe ejecutarse para completar su tarea.
Puede ser por hora, semanal, mensual o puede establecer cualquier otro horario que prefiera.
Cuando agrega un CronJob para su aplicación, hay un área separada en el archivo de configuración para que configure su horario. Además, obtendrá una sección JobTemplate separada en CronJobs que no encontrará en Jobs.
Cabe además mencionar que los Jobs pueden crear uno o más Pods (permitiendo concurrencia/paralelismo) a la vez que se aseguran que las tareas se completan satisfactoriamente. Sin embargo, este último comportamiento podría crear complejidades adicionales ya que los contenedores ya incorporan su propia funcionalidad de gestión de fallos y reinicios.
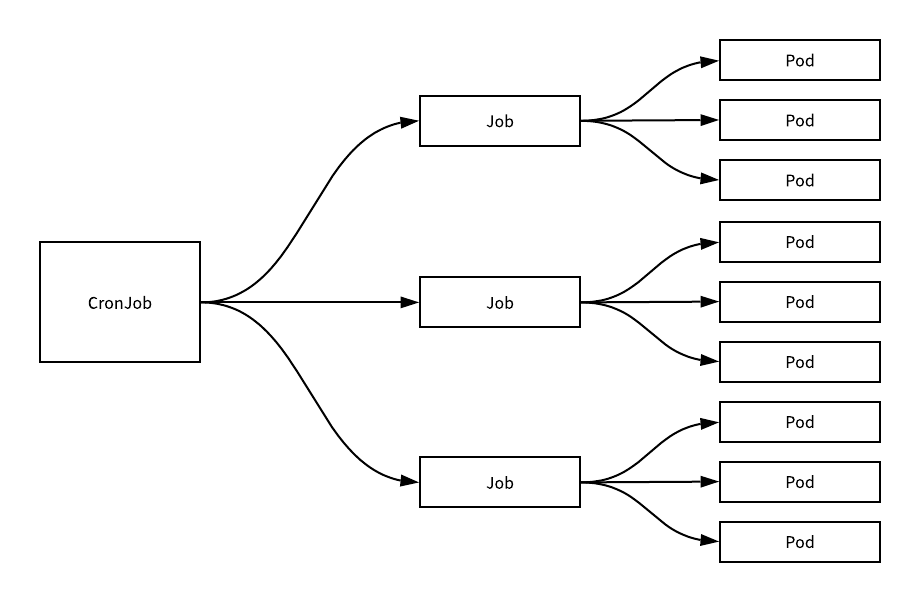
Creemos un CronJob para una aplicación que se ejecuta en Kubernetes.
apiVersion: batch/v1
kind: CronJob
metadata:
name: cron-test
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: cron-test
image: busybox
command: ["/bin/sh"]
args: ["-c", "date; echo Hello this is Cron test"]
restartPolicy: Never
Recomiendo usar https://crontab.guru/ para calcular tiempos para nuestros cron
Vamos aplicarlo en el cluster , taran taran ven CronJob
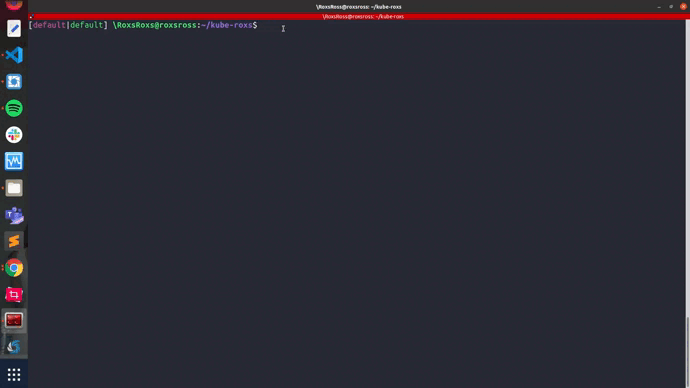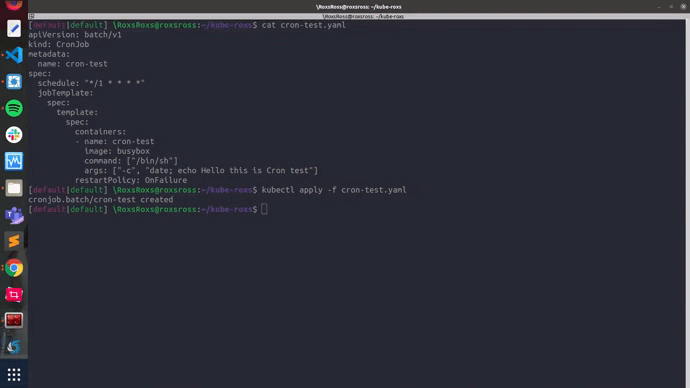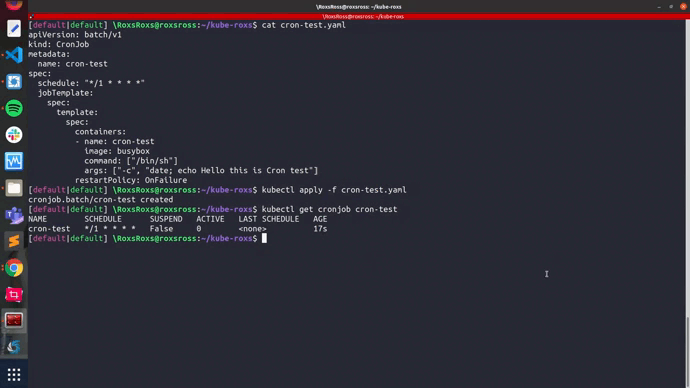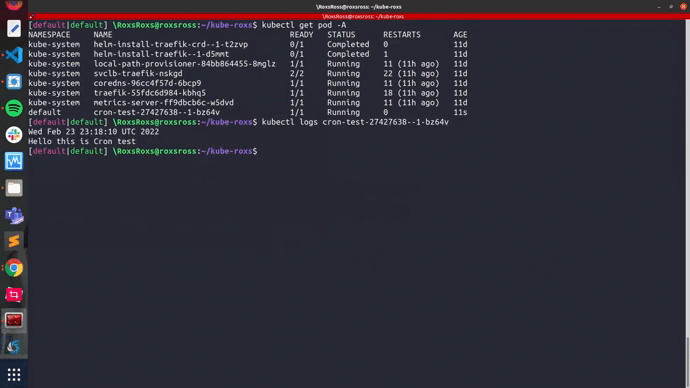
con el ejemplo anterior lo guardamos con el nombre: cron-test.yaml
ahora aplicamos el CronJon en el cluster
$ kubectl apply -f cron-test.yaml
cronjob.batch/cron-test created
Verificamos que el cronJob se ha creado con la definición de scheduler
$ kubectl get cronjob cron-test
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cron-test */1 * * * * False 0 <none> 10s
$ kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system metrics-server-ff9dbcb6c-w5dvd 1/1 Running 11 (11h ago) 11d
default cron-test-27427638--1-bz64v 1/1 Running 0
Después de unos segundos, puede encontrar los pods programado y ver los logs de uno de los pods:
$ kubectl logs cron-test-27427638--1-bz64v
Wed Feb 23 23:18:10 UTC 2022
Hello this is Cron test
Ha creado un CronJob de Kubernetes que crea un objeto una vez por ejecución según la programación schedule: "/1 *".
Cambio schedulede CronJob
* * * * *
- - - - -
| | | | |
| | | | ----- Day of week (0 - 7) (Sunday=0 or 7)
| | | ------- Month (1 - 12)
| | --------- Day of month (1 - 31)
| ----------- Hour (0 - 23)
------------- Minute (0 - 59)
schedule: "0 0 /2 " schedule: "30 8 * 0"
ExitosoJobsHistoryLimit & FailJobsHistoryLimit
En el escenario habitual, Kubernetes mantiene el registro de los últimos 3 cronjobs exitosos y el último cronjob fallido para que cuando ejecute el comando kubectl get all , vea este registro en el historial. Pero en el archivo de configuración de CronJob, puede editar este valor y tener más registros en el historial.
apiVersion: batch/v1
kind: CronJob
metadata:
name: cron-test
spec:
schedule: "*/1 * * * *"
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 1
jobTemplate:
spec:
template:
spec:
containers:
- name: cron-test
image: busybox
command: ["/bin/sh"]
args: ["-c", "date; echo Hello this is Cron test"]
restartPolicy: Never
Suspender el CronJob
Cuando se ejecuta la tarea programada sin tener una suspend sección en su archivo de configuración, se establecerá automáticamente el suspend en false y continuamente ejecutar el trabajo de acuerdo con el programa dado. Además, cuando ejecute el
kubectl get cronjob
comando, verá una salida como la siguiente.
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob * * * * * False 0 <none> 3s
apiVersion: batch/v1
kind: CronJob
metadata:
name: cron-test
spec:
schedule: "*/1 * * * *"
suspend: true
jobTemplate:
spec:
template:
spec:
containers:
- name: cron-test
image: busybox
command: ["/bin/sh"]
args: ["-c", "date; echo Hello this is Cron test"]
restartPolicy: Never
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob * * * * * True 0 <none> 19s
En un escenario real, no se edita el archivo de configuración de CronJob para agregar el suspend: true , en lugar de editar el archivo de configuración, puede usar el kubectl patch comando en su terminal para cambiar este valor.
//patch the cronjob
$ kubectl patch cronjob <cronjob-name> -p '{"spec":{"suspend":true}}'
- OR -
//path the configuration file
$ kubectl patch -f <file-name> -p '{"spec":{"suspend":true}}'
$ kubectl patch cronjob <cronjob-name> -p '{"spec":{"suspend":false}}'
- OR -
$ kubectl patch -f <file-name> -p '{"spec":{"suspend":false}}'
Otras cosas que debe saber
Los servicios en Kubernetes, no puede cambiar el mismo archivo de configuración del trabajo y volver a aplicarlo a la vez. Cuando realiza cambios en el archivo de configuración del trabajo, debe eliminar el trabajo anterior del clúster antes de aplicarlo.
En general, la creación de un trabajo crea un solo pod y realiza la tarea dada, como en el ejemplo anterior. Pero al usar paralelismo , puede iniciar varios pods, uno tras otro.
Mi trabajo de Cron no comenzó a tiempo. ¿Qué tengo que hacer?
En algunos casos, es posible que el CronJob no se active en el momento especificado.
En tal caso, hay dos escenarios:
- Necesitamos ejecutar el job que no comenzó, incluso si se retrasó.
- Necesitamos ejecutar el job que no comenzó solo si no se cruzó un límite de tiempo específico.
Necesito ejecutar el trabajo de Cron solo una vez
En Linux, tenemos el comando. El comando at le permite programar un programa para que se complete, pero solo una vez. Esta funcionalidad se puede lograr usando el recurso CronJob en Kubernetes usando el .spec.suspend
¿Mantiene Cron Job un historial de los trabajos que tuvieron éxito y fallaron?
La mayoría de las veces, necesita saber qué sucedió la última vez que se ejecutó el cronjob. Si no se produjo una actualización de la base de datos, no se actualizó un servidor API o cualquier otra acción que se suponía que debía ocurrir como resultado de la ejecución de CronJob, necesitaría saber por qué. De forma predeterminada, CronJob recuerda los últimos tres trabajos exitosos y el último fallido. Sin embargo, esos valores se pueden cambiar según sus preferencias configurando los siguientes parámetros:
spec.successfulJobsHistoryLimit: si no se establece, el valor predeterminado es 3. Especifica la cantidad de trabajos exitosos que se mantendrán en el historial.
spec.failedJobsHistoryLimit: si no se establece, el valor predeterminado es 1. Especifica la cantidad de trabajos fallidos que se mantendrán en el historial.
Si no necesita mantener ningún historial de ejecución, puede establecer ambos valores en 0.
Conclusión
Puede usar Kubernetes Jobs y CronJobs para administrar sus aplicaciones en contenedores. Los trabajos son importantes en los patrones de implementación de aplicaciones de Kubernetes, donde se necesita un mecanismo de comunicación junto con interacciones entre los pods y las plataformas. Esto puede incluir casos en los que una aplicación necesita un "controlador" o un "observador" para completar tareas o debe programarse para ejecutarse periódicamente.
La pagina Oficial de Kubernetes cuenta con una excelente documentación
Documentacion:
- https://medium.com/@bambash/kubernetes-docker-and-cron-8e92e3b5640f
- https://medium.com/symbl-ai-engineering-and-data-science/time-based-scaling-for-kubernetes-deployments-9ef7ada93eb7
Y como Bonus Track
Usando CronJob puede ahorrarte mucho billing si usas AWS EKS Fargate
Usando AWS EKS con Fargate podemos ejecutar pods sin configurar ningún servidor, y también podemos configurar opciones de escalado basadas en el tráfico (usando, por ejemplo, métricas de CPU/Memoria con HPA).
Entonces, al usar esta técnica de escalado, podemos escalar en horas laborales y reducir nuestras implementaciones para ejecutarlas con al menos 1 pod en horas no laborales para ahorrar dinero; este artículo le muestra cómo.
Pero esos pods tienen un costo asociado y en algunos entornos, como DEV, TEST, UAT, esto significa dinero desperdiciado cuando nadie lo está usando.
Ahorrar dinero con Fargate
¡No olvides volver por el blog para comprobar qué hay nuevo por aquí!




